
Project 6 Imdb


NetFlix has tasked my team, in this project, to examine what factors lead to certain ratings for movies. My approach has been to utilize (IMDb) the Internet Movie Database’s Application Program Interface (API) to pull a listing of Top 250 Movies in the database. Finally, I used Tree-based models and other emsemble machine learning toolkit to guide me in understanding which features could be most important in building future predictive model. SPOILER ALERT: It turns out IMDb User Voting, the year the movie was release in movie theaters, the time it takes a movie to go from being released to general movie theaters to DVD release and to a lesser extent the “Rotten Tomato”-like IMDb metascore are all contributing features to predicting movie ratings.
The IMDB API provided 25 possible features: ‘Actors’, ‘Awards’, ‘BoxOffice’, ‘Country’, ‘DVD’, ‘Director’, ‘Genre’, ‘Language’, ‘Metascore’, ‘Plot’, ‘Poster’, ‘Production’,’Rated’, ‘Ratings’, ‘Released’, ‘Response’, ‘Runtime’, ‘Title’,’Type’, ‘Website’, ‘Writer’, ‘Year’, ‘imdbID’, ‘imdbRating’,’imdbVotes’.
Of these, we feature engineered additional features included: used a count vectorizor to get top words displayed in the Awards feature, Country feature, Genre feature. I created a feature to capture the distinction between elite drectors (like Martin Scorsese, Alfred Hitchcock, Steven Speilberg, Christopher Nolan and Stanley Kubrick) and all other mid-scale directors. The same feature engineering approach was created for “bigger” movie studios (like Warner Bros., Paramount Pictures, United Artist, etc.) versus all other lesser producing Studios. I also created dummy variables to capture movie Ratings system. Finally, I calculated the difference between when a movie was released to the general movie-going public and the date the movie was released to DVD. After imputing mean values (for Released to DVD feature and metascore fields) and after standardizing all non-dummy features, I included all of these features into a decision tree model, that optimizes breaks between nodes (i.e. features) and other emsembles like bagging classifier, random forest, extra trees, ada boost regressor and gradient boost
Why use decision trees to predict IMDb movie ratings? Unlike logistic or linear regression model assumptions, decision trees do not pretend any underlying shape or distribution to the data. Decision trees create an optimal and efficient means of splitting data in the most meaningful way. Additionally, being easily interpretable, decision trees help in feature selection with little data preperation (although we throughly prepped our data here). Now, although “deeper” trees (more nodes or partitions) tend to overfit models, I have implemented a train test split of 67:33 and have kept to not so deep trees. We will evaluate the decision tree based on gini coefficients.
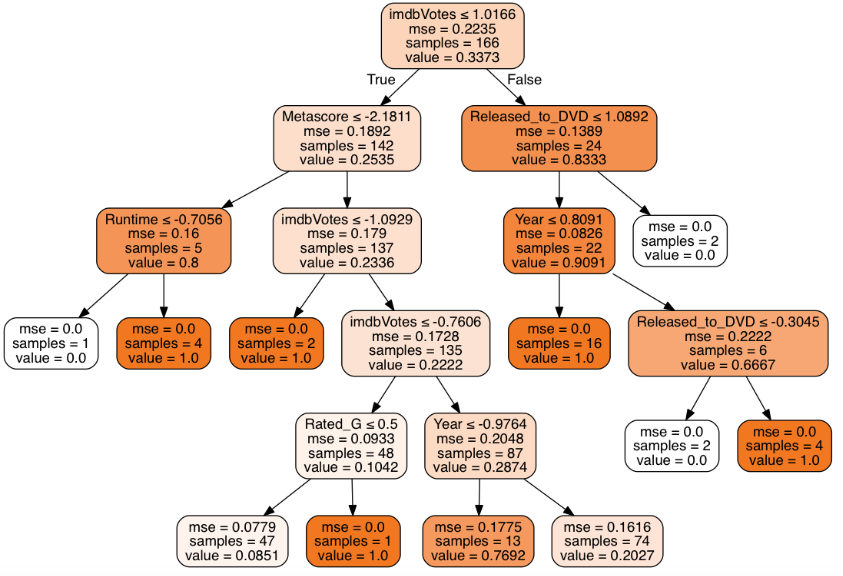
A graphical representation of the decision tree model based on the training data is detailed, here above. Each node (box shapes) represents the feature the decision tree found as best to split on, or where purity is maximized. IMDb User Voting, the year the movie was release in movie theaters, the time it takes a movie to go from being released to general movie theaters to DVD release and to a lesser extent the “Rotten Tomato”-like IMDb metascore are all contributing features to predicting movie ratings. The value coefficient in each node represents the gini coefficient for that node. The closer to 0 the gini score, the more pure the result.
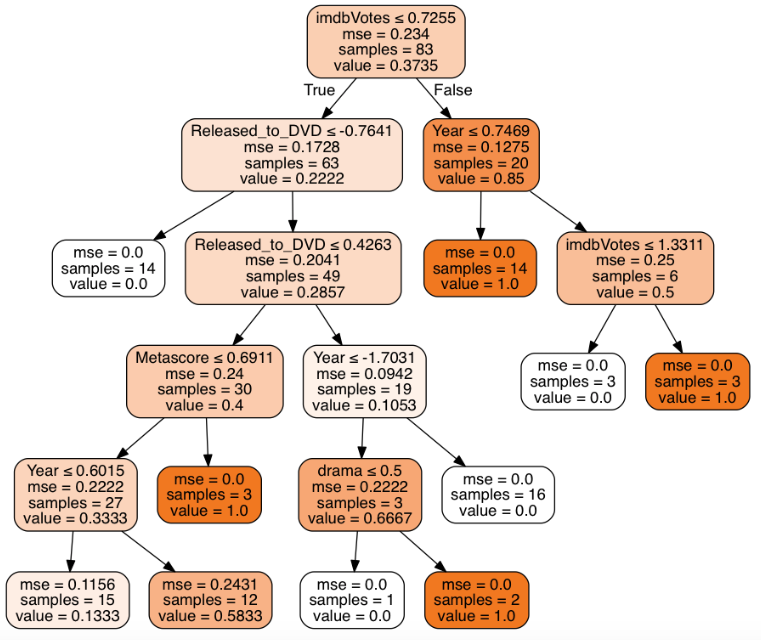
Now as stated above, decision trees and other ensembles do run the risk of overfitting. Could we have potentially over-fit this model, sure but for that reason we have held out test data. The above decision tree shows the following nodes as the most important features are: IMDb User Voting, the year the movie was release in movie theaters, the time it takes a movie to go from being released to general movie theaters to DVD release and to a lesser extent the “Rotten Tomato”-like IMDb metascore are all contributing features to predicting movie ratings. These are the same features as those selected by the decision tree created based on the training data set. These results should be reassuring because the decision tree based on the training and test data are the same with respect to feature importance.
Of the different Ensemble models, the bagging decision tree yielded the best accuracy scores at 0.77 with a 0.05 error metric. Bagging model create a random sample via bootstrapping aggregrating. Therefore I would advise NetFlix that the best tree model is the bagging decision tree. Additionally, the fields stated above are of feature importance that one would consider for further modeling. Following a closer second, random forest model yield a second best accuracy score of 0.74 with 0.06 error score on the training set. In conclusion, we have discovered important features using a variety of decision trees with which to further model.